
1 min read
16S vs Metagenomics: What's the Difference?
In the captivating world of microbiology, two primary methods have emerged to study the composition, structure, and function of microbial...
4 min read
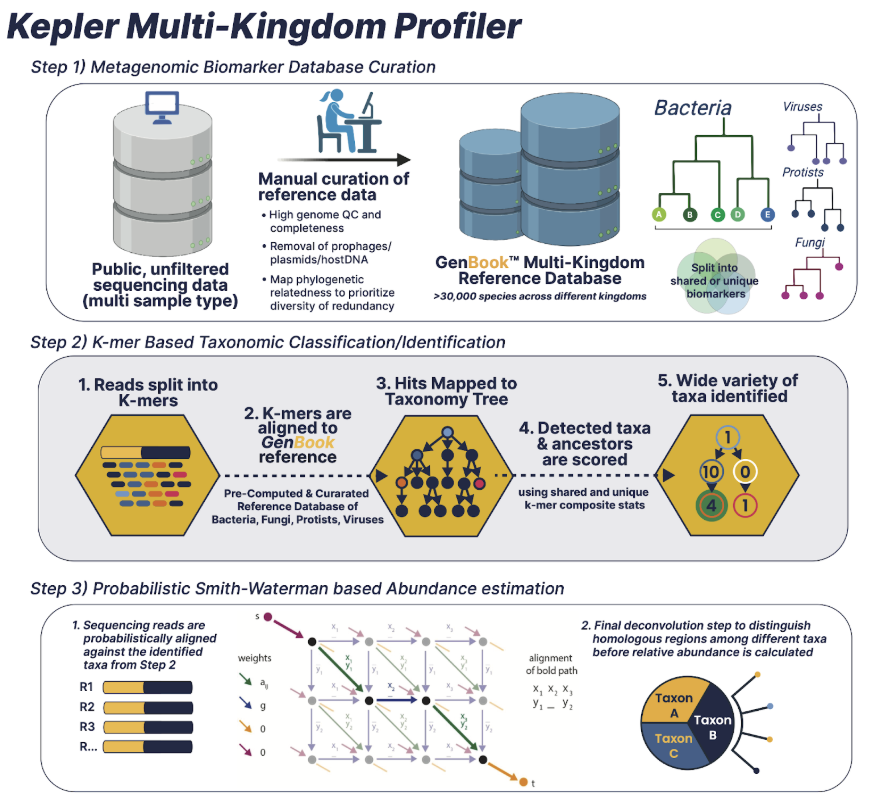
The Kepler metagenomic profiler is a host-agnostic pipeline focused on taxonomic and functional profiling. Powered by Cosmos-Hub, Kepler is accessible via a graphical user interface purpose-built for microbiome analysis and extensible to other scientific domains.
The pipeline enables users to execute computational tools and connect pertinent analytical components with minimal effort, helping researchers and programmers create scientific workflows, compose structured sets of input parameters, and integrate a broad range of analytical and statistical database management processes.
In this article, we'll look at how the Kepler Workflow combines curated genomic databases, phylogenetic biomarkers, and a 2-phase computational pipeline to deliver high-precision, multi-kingdom microbiome profiling—covering bacteria, viruses, fungi, and protists—alongside functional and resistome analysis for applications in clinical, environmental, and population health research.
Kepler is a multi-kingdom taxonomic profiling pipeline engineered for microbiome research. It utilizes a meticulously curated database and advanced computational algorithms to accurately identify bacteria, viruses, fungi, and protists from metagenomic data.
Kepler’s approach leverages high-completeness genome references and unique k-mer biomarkers, delivering robust results even from challenging, low-biomass, or host-contaminated samples. The Kepler project supports researchers to benefit from sensitivity, precision, and broad applicability across diverse domains—including clinical diagnostics, environmental science, and population health.
Kepler pipeline integrates a range of specialized steps that streamline the microbiome analysis workflow. The comprehensive algorithm consists of three interwoven pipelines:
At the foundation of GenBook™, our pre-computational curation process ensures you are working with the most accurate and comprehensive microbial genome database available. We begin by selecting only the highest quality microbial genomes, filtering out contamination, redundant assemblies, and low-complexity sequences to maintain signal integrity.
This results in a database of more than 180,000 genes and genomes covering 30,000 species across bacteria, viruses, protists, fungi, and phages—built to provide researchers with a trusted and diverse reference library for microbiome profiling.
The first stage of classification applies k-mer based identification, where millions of sequencing reads are broken into k-mer sets and compared against GenBook™ biomarkers.
This process rapidly filters out 99% of irrelevant genomes and delivers a shortlist of the most likely reference strains. By working at the sub-species level with exceptional sensitivity, this stage offers precise taxonomic resolution and ensures that researchers can quickly zero in on the organisms that matter most in their samples.
To refine accuracy further, we deploy a probabilistic Smith-Waterman algorithm for abundance estimation and classification. This step evaluates the remaining candidate strains in detail, resolving ambiguous reads and proportionally allocating them across taxa using maximum likelihood estimation. The result is highly accurate, variance-reduced abundance data that researchers can rely on for confident decision-making.
Together, these staged comparators allow Kepler to deliver the most precise and reliable microbial classification and quantification available.
Kepler extends core taxonomic capabilities with functional and resistome profiling modules. The platform links microbial pathway annotation, gene function mapping, and antimicrobial resistance detection within a unified analysis path, via:
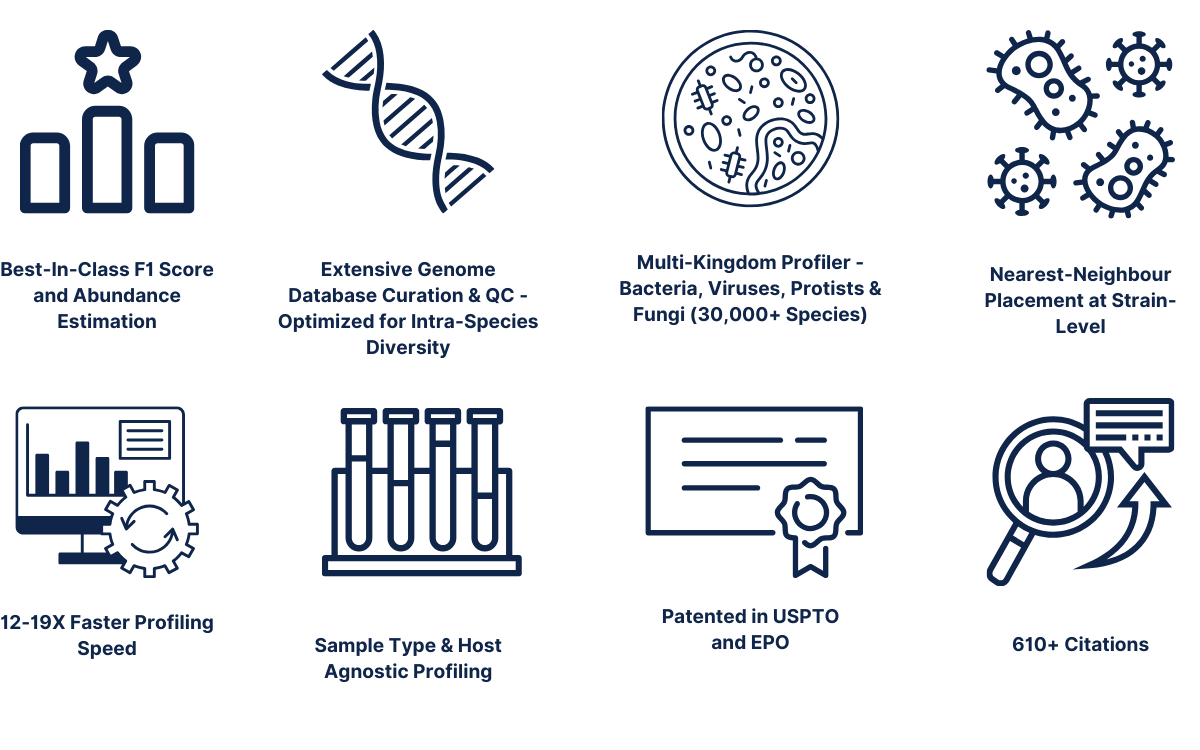
Key benefits include:
The papers have cited the Cosmos-Hub in their methodology. Consult these for direct examples:
|
Metric |
Kepler |
MetaPhlAn4 |
Kraken2 |
|
Species Sensitivity |
Highest |
High |
Low |
|
Sub-species Detection |
Yes |
Limited |
Limited |
|
False Positive Rate |
Lowest |
Highest |
Moderate |
|
Virus/Fungi Detection |
Yes |
No |
Limited |
|
Resistome Analysis |
Yes |
No |
No |
|
Computational Speed |
Fastest |
Longest |
Moderate |
Kepler provides host-agnostic profiling and multi-kingdom detection, connecting pertinent analytical components for comprehensive workflow analysis. The extensible system allows integration of computational tools, database management, and automation, empowering large-scale data execution across scientific and engineering disciplines.
Applications span diagnostics, environmental research, animal health studies, and population health studies, supported by accurate scientific workflows, statistical database management, and robust computational tools.
Kepler combines exact k-mer match profiling with probabilistic alignment and a unique phylogenetic biomarker tree, achieving superior species and sub-species sensitivity, lower false positives, and multi-kingdom detection—covering viruses and fungi, not just bacteria.
Absolutely. Kepler supports host-agnostic profiling, excelling in environmental microbiome mapping (soil, plants, animals) as well as clinical contexts.
Yes. The Kepler software package integrates direct resistome analysis via ResFinder and VFDB, quantifying ARGs and mapping virulence factors for surveillance and research.
1 min read
In the captivating world of microbiology, two primary methods have emerged to study the composition, structure, and function of microbial...
1 min read
In the realm of microbiology, understanding the intricate workings of microbial communities has become a cornerstone of scientific inquiry. Two...

1 min read
Background