
1 min read
DADA2 Software: Microbiome Data Processing
DADA2 is an open-source R package for accurate sample inference on amplicon sequencing data, outputting fewer spurious sequences while generating...
3 min read

A bioinformatics pipeline is the central engine driving microbiome analysis, turning raw sequencing data into interpretable results. Every aspect of successful microbiome research, from quality control to AI-driven insights, depends on specialized bioinformatics pipeline frameworks and workflow management systems.
In this guide, Cosmos-Hub, a leading bioinformatics pipeline platform, exemplifies how integrated, no-code solutions make analysis accessible for researchers across disciplines.
Bioinformatics pipelines are structured, automated sequences of software tools and analysis steps designed specifically to handle data from next generation sequencing (NGS) and other genomic technologies. These pipelines encompass:
Pipelines provide automation, scalability, computational reproducibility, and collaborative biomedical analyses for projects ranging from a handful of samples to large volumes of sequencing data.

A modern bioinformatics workflow engine integrates several pipelines for life sciences applications. Key attributes include:
Pipelines begin with raw sequencing data ingestion. Quality control modules automatically flag anomalies, filter low-quality reads, merge paired-end files, and ensure data integrity, leveraging shareable analysis pipelines and standardized analysis tools.
After preprocessing, metagenomic data flows through software tools for reference genome mapping, abundance estimation, and functional annotation. Cosmos-Hub’s platform structures this with:
Bioinformatics workflow managers enable collaborative development and analysis, especially for microbiome studies and multi-team/institutional projects. Cosmos-Hub incorporates cloud-based AWS architecture for secure sharing, version controlled pipelines, multi-factor authentication, and robust role-based permissions for Enterprise Solutions.
A scalable pipeline framework must integrate public databases and support comparative meta-analysis. Cosmos-Hub’s Atlas database provides over 40,000 global samples for benchmarking, amplifying the statistical strength of empirical studies and fostering wider adoption in the community.
While metabolomics capabilities are planned for launch in late-2025, Cosmos-Hub currently supports sequencing types like 16S, ITS, and shotgun metagenomics. Multi-omics support allows pipelines to layer genomics with transcriptomics, proteomics, or metabolomics, positioning bioinformatics resources for future comprehensive research.
No-code platforms like Cosmos-Hub democratize pipeline access:
|
Feature |
Traditional Workflow |
Cosmos-Hub Bioinformatics Workflow |
|
Pipeline Coding and Maintenance |
Required |
Not required |
|
Error Rate (false positives/negatives, incorrect parameters) |
Higher |
Lower, automated |
|
Collaboration |
Limited |
Secure, multi-user, accessible via GUI |
|
Scalability |
Project, team, and institution dependent |
Cloud-based, scalable |
|
AI Interpretation |
Seldom available |
Standard via RITA AI |
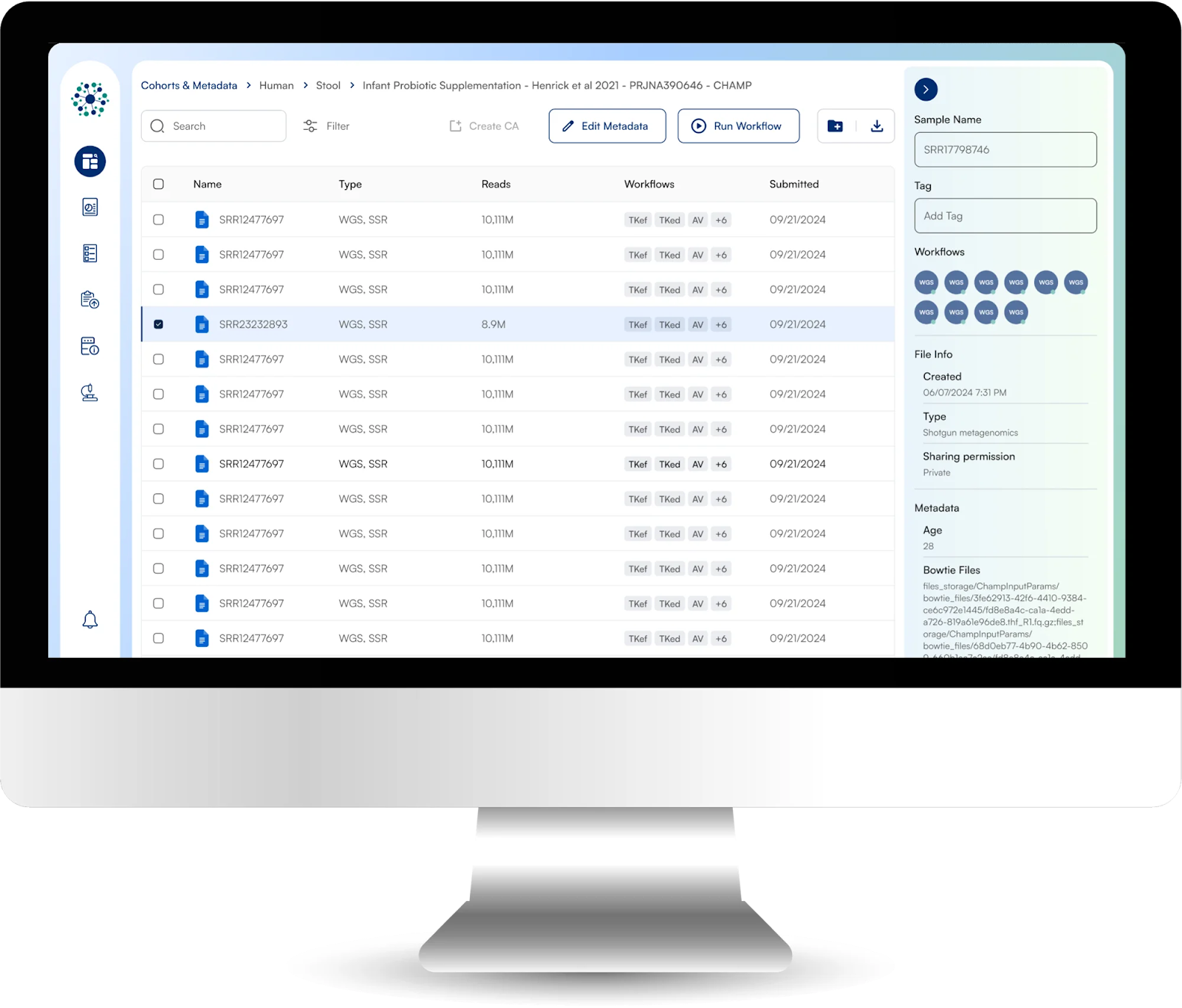
Bioinformatics pipelines are indispensable for extracting actionable insights from next generation sequencing data. Their frameworks ensure computational reproducibility and foster collaborative scientific advancement in genomics, nutrition, pharmaceuticals, and beyond. These pipelines provide significant advantages that elevate the quality and efficiency of microbiome research:
With enterprise plans designed to tailor collaborative solutions for your research team, Cosmos-Hub empowers users with the pipeline tools required to transform raw data into scientific discoveries—securely, efficiently, and at scale. Join the Metabolomics Waitlist to prepare for future multi-omics analysis.
The five essential components are data ingestion, quality control, profiling and annotation, statistical analysis, and interpretation. In a pipeline, these stages collectively convert raw biological data into actionable scientific insights using modular software tools and workflow systems.
To create a bioinformatics pipeline, define the analytical goals and select appropriate software tools for each step (data download, quality filtering, profiling, statistical analysis, and visualization) then configure these modules to operate in a standardized, automated sequence. Platforms like Cosmos-Hub allow researchers to do this via graphical interfaces, making pipeline assembly accessible without advanced coding.
A pipeline in sequencing is a structured workflow of multiple tools that processes raw sequencing data through critical steps such as quality control, taxonomic assignment, and statistical analysis. The pipeline automates and standardizes the transformation of sequencing reads into reliable biological insights, vital for large-scale genomics projects.
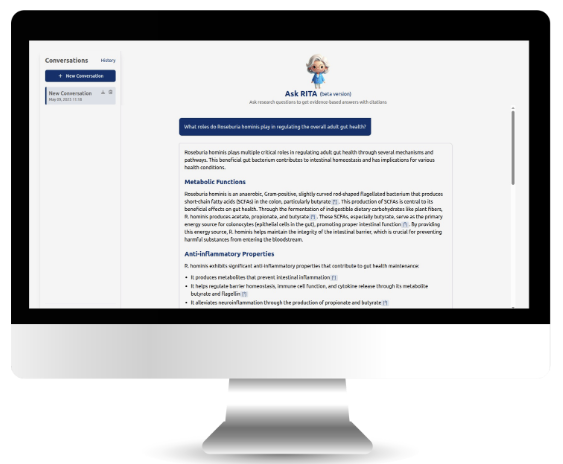
1 min read
DADA2 is an open-source R package for accurate sample inference on amplicon sequencing data, outputting fewer spurious sequences while generating...
1 min read
In the realm of microbiology, understanding the intricate workings of microbial communities has become a cornerstone of scientific inquiry. Two...
1 min read
Glyphosate-based herbicides have been extensively used in agriculture, mainly due to the prevalence of genetically modified, glyphosate-resistant...